
이 글을 작성하게 된 이유
이번 프로젝트에서는 gRPC 기반의 채팅 서비스를 새롭게 구현하면서, 이미지 전송까지 마무리한 뒤 PR을 올리고 뿌듯해하던 중,
팀원으로부터 “페이징을 적용해보면 좋을 것 같다”는 코드 리뷰를 받았습니다.
사실 저도 페이징을 고려하고 있었기에 “좋은 기회다” 싶어 성능 개선을 목표로 페이징을 직접 적용했습니다.
그리고 여러 페이징 기법 중 어떤 방식을 선택했고, 왜 그렇게 결정했는지를 정리해두면 좋을 것 같아 이 글을 작성하게 되었습니다.
페이지네이션이란?
검색결과를 가져올 때 데이터를 쪼개 번호를 매겨 일부만 가져오는 기법입니다.
왜 사용했는가?
사용자가 채팅방에 들어올 때, 모든 채팅 내역을 한 번에 조회한다면 어떨까요?
채팅이 10개, 20개 정도일 때는 큰 문제가 없지만, 내역이 1만 개, 10만 개로 늘어난다면 이야기가 달라집니다.
조회 속도가 느려지고, 화면이 한 번에 많은 데이터를 처리해야 하므로 사용자 입장에서는 점점 불편함을 느끼게 됩니다.
이런 문제를 해결하기 위해 페이징(Paging) 을 적용했습니다.
데이터를 한 번에 전부 가져오는 대신, 필요한 만큼만 나눠서 가져오고,
사용자가 스크롤을 내리거나 ‘이전 대화 더보기’를 눌렀을 때 다음 데이터를 요청하도록 설계하면
조회 성능을 유지하면서도 사용자 경험(UX) 을 향상시킬 수 있습니다.
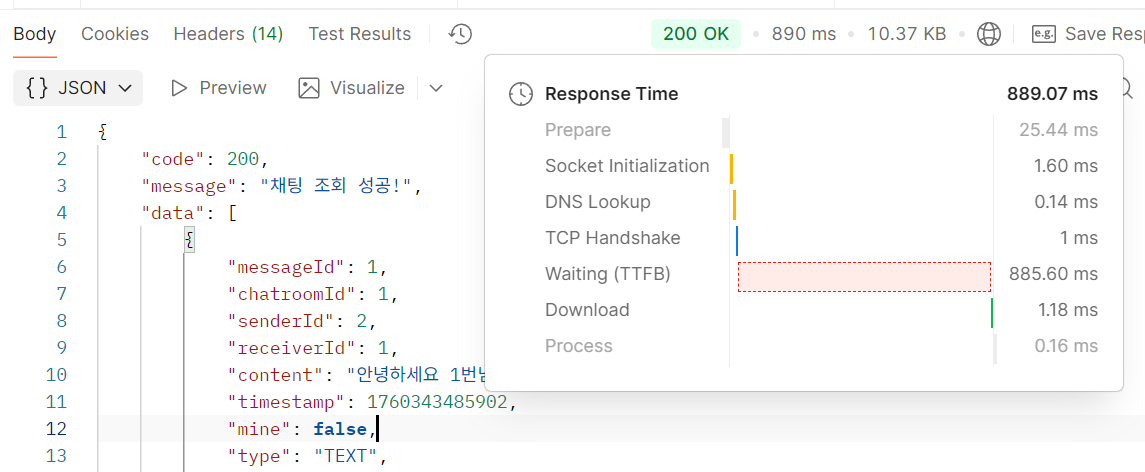
890ms로 50건임에도 불구하고 느린 것을 알 수있습니다.

100건이 된 순가 1.09s로 느린것을 확인했고, 메시지가 더 많아지면 조회 성능이 안좋아질 것이라고 예상했습니다.
적용하기로 마음 먹은 후, 페이지네이션에 대해 공부를 했습니다.
오프셋 기법과 페이징 기법 2가지가 존재했습니다.
페이징 종류
1. 오프셋(Offset) 방식:
데이터를 페이지 단위로 나누어 조회할 때, 기준점(offset)부터 특정 개수(limit)만큼 데이터를 가져오는 방식입니다.
Spring 프레임워크의 pagenable 인터페이스는 offset방식으로 이루어져 있습니다.
select *
from post
order by create_at desc
limit 10, 20;
JPA를 사용하면 추가적인 설정 없이도 구현할 수 있지만 해당 방식의 단점을 봤을 때 실시간 채팅에 적합한 방식은 아니라고 생각했기 때문에 사용하지는 않았습니다.
1-1. 오프셋 장점 및 단점
장점
- 간편한 구현: 구현이 직관적이고 쉽습니다. 클라이언트는 단순히 페이지 번호와 페이지당 데이터 수를 전달하면 됩니다.
- 빠른 페이지 이동: 사용자가 원하는 특정 페이지로 즉시 이동할 수 있습니다.
단점
- 성능 저하: 데이터 양이 많아질 수록 성능이 느려집니다.
페이지를 건너뛸 때마다 데이터베이스는 해당 페이지까지의 모든 이전 데이터를 읽어야하기 때문입니다.
offset 값이 작을 때는 상관이 없습니다.select * from post order by create_at desc limit 10 offset 100000000;
하지만, offset이 커지면 커질 수록 느려진다는 단점이 있습니다.
예를 들어 위의 쿼리는 1억번째부터 10개를 가져오라는 쿼리가 실행이 되면 1억번째까지 데이터를 나열해야하므로 속도가 느려집니다.

- 데이터 중복 문제: 데이터 추가, 삭제가 빈번할 경우 중복되거나 누락된 데이터가 발생할 수 있습니다.
예를 들어, 페이지를 요청하는 사이에 새로운 데이터가 추가되거나 기존 데이터가 삭제되면 문제가 생길 수 있습니다.- 10개의 글이 있는 게시판으로 예시를 들어보면
1. A 사용자가 첫 메인페이지에 진입합니다.
2. 최신 게시글을 보여주기 위해 id가 10~6인 게시글을 가져와서 보여줍니다.
select * from post order by id desc limit 5 # 가져올 개수 offset (0*5) # (몇 번째 페이지인지 * 가져올 개수)
3. A 사용자가 구경하는 사이 다른 사용자들이 새로운 게시글 3개를 생성합니다.
4. A사용자가 게시글을 다 구경하고, 다음 페이지 버튼을 눌러 요청합니다.
select * from post order by id desc limit 5 # 가져올 개수 offset (1*5) # (몇 번째 페이지인지 * 가져올 개수) == 5개 데이터를 건너뛰어라- 현재 총 게시글 개수는 13입니다.
- 그러면 id가 8번부터 ~ 4번 게시글을 가져오게 됩니다.
- 이렇게 되면 id가 8,7,6인 게시글을 또 가져오게 됩니다. -> 데이터 중복 발생!!!!
- 10개의 글이 있는 게시판으로 예시를 들어보면
- 비효율적 리소스 사용: 오프셋이 커질수록 데이터베이스는 더 많은 데이터를 읽고 넘어가야 하므로, 리소스 낭비가 발생할 수 있습니다.
2. 커서(Cursor) 방식:
Cursor는 어떠한 레코드를 가리키는 포인터를 의미합니다.
이 Cursor가 가리키는 레코드로부터 일정 갯수만큼 가져오는 방식이 Cursor 페이징 방식입니다.
쉽게 말하면
사용자에게 응답해 준 마지막의 데이터의 식별자 값이 Cursor가 됩니다.
해당 Cursor를 기준으로 다음 n개의 데이터를 응답해주는 방식입니다.
마지막으로 읽은 데이터(1억번)의 다음 데이터부터 10개의 데이터를 조회 -> 10개의 데이터만 조회
그러므로 어떤 페이지를 조회하는 항상 원하는 데이터 개수만큼 읽기 때문에 성능상 이점이 존재합니다.
1. 첫 페이지에 진입했을 때의 쿼리는 그냥 limit으로 10개 잘라서 줍니다.
2. 이후 페이지에 대한 요청은 사용자에게 응답한 데이터 중 마지막 게시글이 cursor가 됩니다.
2-2. 커서 장점 및 단점
장점
- 실시간 데이터에 강함: 데이터가 실시간으로 변경되는 상황에서 일관성을 유지합니다. 이전 데이터의 삭제나 새로운 데이터의 추가가 다음 페이지 로드에 영향을 주지 않습니다.
- 대규모 데이터 성능: 데이터 양이 많아질 수록 오프셋 방식의 성능 저하 문제를 해결할 수 있습니다.
- 데이터 일관성: 특정 커서 이후 데이터를 요청하기 때문에 데이터가 변경되어도 결과의 일관성을 보장합니다.
단점
- 페이지 점프 불가: 특정 페이지 번호로 바로 이동할 수 없습니다.
-> 제가 구현하려는 실시간 채팅에서는 의미없는 단점입니다. - 유니크한 기준 필요 : Where 절에 사용될 기준이 반드시 유니크해야합니다. 중복되는 값을 기준으로 할 경우 정확하지 않은 결과가 나올 수 있어, 복합 키를 사용하거나 유니크 키를 포함해야합니다.
-> 메시지id와 createdAt 을 복합키로 사용하여 Base64로 인코딩해서 사용했습니다. - 정령 기준 고정: 커서를 생성한 시점의 정렬 기준이 절대적입니다.
-> 채팅방에 들어가면 최신 메시지 먼저 보이기 때문에 이 또한 괜찮습니다. - 구현의 복잡성: 오프셋 방식보다는 복잡합니다.
Cursor 기반 페이지네이션 구현하기
- 요청 파라미터 해석
- chatroomId, cursor, limit, isAfter(AFTER/BEFORE 방향)
- 커서 디코딩
- CursorUtil.decode(cursor) -> (ts,id) 복합키 복원 (UTC epochMillislid를 Base64로 인코딩/디코딩)
- 분기
- 첫페이지(Cursor 없음) : findRecent(최신부터)
- 과거 더보기(BEFORE) : findBefore(< 비교)
- 새 메시지(AFTER) : findAfterAsc(ASC로 받아 reverse)
-> 응답은 항상 최신이 위인 DESC 정렬 유지
- 이미지 조인
현재 페이지 메시지들의 id IN(...) 한 번으로 가져와서 Map 에 묶음 - DTO 매핑
- Message 엔티티 -> ChatMessageResponseDTO
- 커서 생성
- prevCursor = 첫 행(가장 최신) 기준 → AFTER용
- nextCursor = 마지막 행(가장 오래) 기준 → BEFORE용
- Slice.hasNext()로 hasMore 결정
ChatServiceImpl
Pageable pageable = PageRequest.of(
0,
limit > 0 ? Math.min(limit, 200) : 20,
Sort.by(DESC, "createdAt").and(Sort.by(DESC, "id"))
);
- 한 페이지 크기 제한(기본 20, 최대 200)
CursorUtil.Decoded cur = (cursor == null || cursor.isBlank()) ? null : CursorUtil.decode(cursor);
- 커서 복원 실패/ 빈 문자열이면 첫 페이지
if (cur == null) {
slice = chatRepository.findRecent(chatroomId, pageable);
} else if (isAfter) {
Slice<Message> asc = chatRepository.findAfterAsc(chatroomId, cur.ts(), cur.id(), pageable);
List<Message> reversed = new ArrayList<>(asc.getContent());
Collections.reverse(reversed);
slice = new SliceImpl<>(reversed, pageable, asc.hasNext());
} else {
slice = chatRepository.findBefore(chatroomId, cur.ts(), cur.id(), pageable);
}
- findAfterAsc는 커서보다 “큰 값”을 ASC로 받아오는 게 인덱스 스캔에 자연스럽기 때문에 그렇게 설계. 클라이언트 일관성을 위해 서비스에서 reverse해서 항상 DESC로 내려줌.
- SliceImpl로 hasNext/페이지 정보 유지.
// 이미지 조인 — 현재 페이지 메시지 id만 대상으로 IN 조회
List<Long> ids = messages.stream().map(Message::getId).toList();
Map<Long, List<String>> imageMap = new LinkedHashMap<>();
if (!ids.isEmpty()) {
for (MessageImage mi : messageImageRepository.findAllByMessageIdIn(ids)) {
if (mi == null || mi.getMessage() == null) continue;
Long mid = mi.getMessage().getId();
String url = mi.getImageUrl();
if (url == null || url.isBlank()) continue;
imageMap.computeIfAbsent(mid, k -> new ArrayList<>()).add(url);
}
}
// 커서 생성
if (!messages.isEmpty()) {
Message first = messages.get(0);
Message last = messages.get(messages.size() - 1);
prevCursor = CursorUtil.encode(first.getCreatedAt(), first.getId()); // AFTER용
nextCursor = CursorUtil.encode(last.getCreatedAt(), last.getId()); // BEFORE용
}- prevCursor: 화면의 가장 위(최신)로부터 “새로운 쪽”을 더 받을 때 쓸 커서
- nextCursor: 화면의 가장 아래(오래된)로부터 “과거 더보기” 할 때 쓸 커서
전체 코드
@Override
public MessagesSliceDTO getMessagesByCursor(Long chatroomId, String cursor, int limit, boolean isAfter) {
Pageable pageable = PageRequest.of(
0,
limit > 0 ? Math.min(limit, 200):20,
Sort.by(Sort.Direction.DESC, "createdAt").and(Sort.by(Sort.Direction.DESC, "id"))
);
CursorUtil.Decoded cur = (cursor == null || cursor.isBlank()) ? null : CursorUtil.decode(cursor);
Slice<Message> slice;
if(cur == null){
slice = chatRepository.findRecent(chatroomId, pageable);
}else if (isAfter) {
// AFTER는 ASC로 뽑아와서 역순으로 바꿔서 응답은 항상 DESC
Slice<Message> asc = chatRepository.findAfterAsc(chatroomId, cur.ts(), cur.id(), pageable);
List<Message> reversed = new ArrayList<>(asc.getContent());
Collections.reverse(reversed);
slice = new SliceImpl<>(reversed, pageable, asc.hasNext());
} else {
slice = chatRepository.findBefore(chatroomId, cur.ts(), cur.id(), pageable);
}
List<Message> messages = slice.getContent();
boolean hasMore = slice.hasNext();
//이미지 조인(현재 페이지 메시지만)
List<Long> ids = messages.stream().map(Message::getId).toList();
Map<Long, List<String>> imageMap = new LinkedHashMap<>();
if(!ids.isEmpty()){
for(MessageImage mi : messageImageRepository.findAllByMessageIdIn(ids)){
if (mi == null || mi.getMessage() == null) continue;
Long mid = mi.getMessage().getId();
String url = mi.getImageUrl();
if (url == null || url.isBlank()) continue;
imageMap.computeIfAbsent(mid, k -> new ArrayList<>()).add(url);
}
}
//dto변환
List<ChatMessageResponseDTO> items = messages.stream()
.map(m->{
long ts = m.getCreatedAt() == null ? 0L
: m.getCreatedAt().atZone(ZoneId.of("Asia/Seoul")).toInstant().toEpochMilli();
return ChatMessageResponseDTO.builder()
.messageId(m.getId())
.chatroomId(m.getChatroom().getId())
.senderId(m.getSenderId())
.receiverId(m.getReceiverId())
.content(m.getContent())
.timestamp(ts)
.type(m.getMessageType() != null ? m.getMessageType().name() : MessageType.TEXT.name())
.imageUrls(imageMap.getOrDefault(m.getId(), List.of()))
.build();
})
.toList();
String prevCursor ="";
String nextCursor ="";
if(!messages.isEmpty()){
Message first = messages.get(0);
Message last = messages.get(messages.size()-1);
prevCursor = CursorUtil.encode(first.getCreatedAt(), first.getId()); // AFTER용
nextCursor = CursorUtil.encode(last.getCreatedAt(), last.getId()); // BEFORE용
}
return MessagesSliceDTO.builder()
.items(items)
.prevCursor(prevCursor)
.nextCursor(nextCursor)
.hasMore(hasMore)
.build();
}ChatRepository
JPQL을 사용해서 구현했습니다.
첫 페이지: 최신부터
@Query("""
select m from Message m where m.chatroom.id = :chatRoomId
order by m.createdAt desc, m.id desc
""")
Slice<Message> findRecent(@Param("chatRoomId") Long chatRoomId, Pageable pageable);
BEFORE: 커서 이전(older)
@Query("""
select m
from Message m
where m.chatroom.id = :chatRoomId
and (
m.createdAt < :lastTimeStamp
or (m.createdAt = :lastTimeStamp and m.id < :lastId)
)
order by m.createdAt desc, m.id desc
""")
Slice<Message> findBefore(...);
AFTER: 커서 이후(newer) - ASC로 뽑아서 서비스에서 reverse
@Query("""
select m
from Message m
where m.chatroom.id = :chatRoomId
and (
m.createdAt > :firstTimeStamp
or (m.createdAt = :firstTimeStamp and m.id > :firstId)
)
order by m.createdAt asc, m.id asc
""")
Slice<Message> findAfterAsc(...);- 커서보다 “새로운” 데이터 → > 비교. ASC로 올리고 역순.
반환을 Slice로 한 이유: count(*) 없이 limit+1로 hasNext 판단 → 더 빠름.
전체코드
//첫 페이지(커서 없음) : 최신부터
@Query("""
select m from Message m where m.chatroom.id = :chatRoomId
order by m.createdAt desc, m.id desc
""")
Slice<Message> findRecent(
@Param("chatRoomId") Long chatRoomId,
Pageable pageable
);
// BEFORE : 커서 이전(과거 더 보기)
@Query("""
select m
from Message m
where m.chatroom.id = :chatRoomId
and( m.createdAt < :lastTimeStamp
or
(m.createdAt = :lastTimeStamp and m.id < :lastId
)
)
order by m.createdAt desc, m.id desc
""")
Slice<Message> findBefore(
@Param("chatRoomId") Long chatRoomId,
@Param("lastTimeStamp") LocalDateTime lastTimeStamp,
@Param("lastId") Long lastId,
Pageable pageable
);
// AFTER: 커서 이후(새 메시지) — ASC로 뽑아 서비스에서 reverse하여 응답은 항상 DESC 유지
@Query("""
select m
from Message m
where m.chatroom.id = :chatRoomId
and(
m.createdAt > :firstTimeStamp
or(m.createdAt = :firstTimeStamp and
m.id > :firstId)
)
order by m.createdAt asc, m.id asc
""")
Slice<Message> findAfterAsc(
@Param("chatRoomId") Long chatRoomId,
@Param("firstTimeStamp") LocalDateTime firstTimeStamp,
@Param("firstId") Long firstId,
Pageable pageable
);
}엔티티 인덱스
@Entity
@Table(name="message", indexes={
@Index(name="idx_chat_message_room_ts_id", columnList="chatroom_id, created_at, id")
})
public class Message extends BaseEntity { ... }
- WHERE와 ORDER BY를 동시에 커버하도록 (chatroom_id, created_at, id) 순서
- (chatroom_id, created_at, id) 이유: WHERE chatroom_id = ?로 먼저 방 집합을 좁히고, 그 안에서 (created_at, id) 범위+정렬을 한 번에 처리(인덱스 범위 스캔).
- 이 인덱스가 있어야 keyset 조건(>, < + order by)을 효율적으로 탐색 가능
적용 후 속도
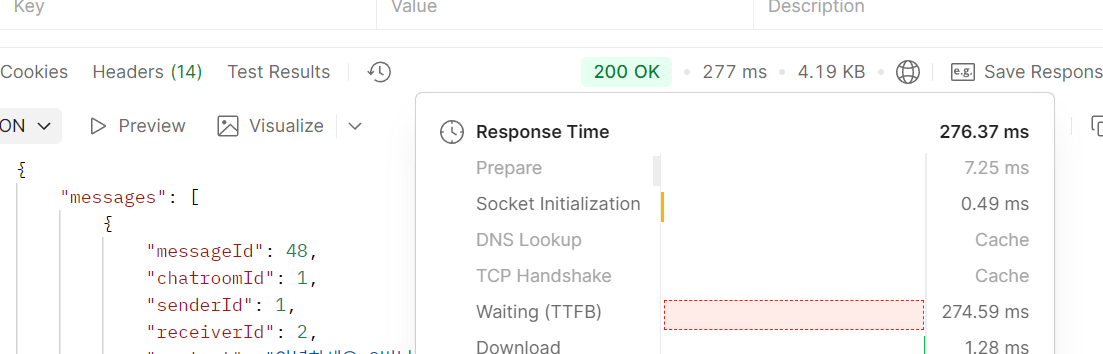
277ms로 줄어든 것을 확인할 수 있습니다.
| 방식 | 조회 수 | 소요시간 |
| 기존 전체 조회 | 50건 | 890ms |
| 커서 기반 페이징 적용 후 | 20건 | 277ms |
데이터 개수가 다르므로, 1건당 평균 조회 시간을 추정해보자면
- 기존: 890ms / 50 건 = 17.8ms / 건
- 커서 페이징: 277ms / 20건 = 13.9 ms/건
평균 처리 속도로 보면 즉 약 22 % 성능 향상입니다.
데이터가 많아지면 많아질 수록 효과는 더 커질 것이라 예상합니다.
'PROJECT' 카테고리의 다른 글
| gRPC 채팅 스트림에서 트랜잭션이 적용되지 않았던 이유(feat. 자기 호출, 프록시) (1) | 2025.10.16 |
|---|---|
| [Spring Security + JWT] 세션 기반 인증에서 JWT로 전환 회고 (0) | 2025.10.14 |